推荐Menci神犇的Blog,KMP讲的很清晰。 在这里把Menci的学习思路复述一遍,以更好地理解KMP。 KMP 学习笔记-Menci
字符串匹配朴素算法
字符串匹配就是在目标串中寻找模式串。
在朴素算法中,我们穷举每一个可以开始匹配的位置,然后逐一比较,如果无法匹配就向右移动一位模式串,直到找到匹配或者所有位置都无法匹配位置。
我们来看一个例子。
当匹配到目标串的第7个字符时,发生了失配:
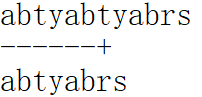
按照朴素算法,我们需要把模式串右移一个单位,再进行匹配;发现不能匹配,就再右移……

时间复杂度为$O(l_1 l_2)$,其中$l_1,l_2$分别为目标串和模式串的长度。
KMP算法原理
从上图我们可以发现,与其说将模式串右移一个单位,不如直接把目标串中第二个ab和模式串的开头的ab(注意不是abty)相互对齐:
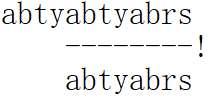
这样就不用从模式串第一个位置开始重新匹配,减少了模式串的右移次数。
KMP算法的原理就是优化失配的情况,充分利用失配时的已匹配信息,每次失配时,如上图一样把模式串中已匹配部分的前缀和目标串中已匹配部分的后缀互相对齐,再继续匹配;如上图中,ab既是已匹配部分的前缀,又是已匹配部分的后缀。请仔细体会这句话。
需要注意的地方
如果已经匹配的部分有着多个相同的前后缀呢?考虑下面这个例子:
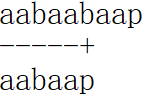
a和aa都是已经匹配部分的前后缀。如果我们按照a对齐:
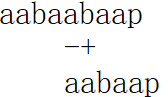
最终结果是匹配失败。
但是如果我们按照aa对齐:
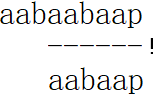
最终匹配成功。
因此,当已经匹配的部分有着多个相同的前后缀时,要尽可能选择较长的那个,否则会错过可能的匹配。
实现
如何找出已经匹配的部分的前后缀呢?
容易发现,已经匹配的部分与目标串无关,只与模式串有关。
因此,我们考虑预处理模式串,递推求出前后缀信息。设目标串为$a$,模式串为$b$。
令字符串的下标从1开始,fail[i]表示从模式串第1位到第i位的最长的相同前后缀长度。
考虑分fail[i-1]是否为零,以及当前的前后缀对应字符,即第i个字符和第fail[i-1]+1个字符是否相同,进行讨论。
1. $fail[i-1]=0$
- b[i]=b[1] 此时直接有fail[i]=1,即当前字符与模式串第一个字符构成了相同的前后缀。
- b[i]!=b[1] 同理有fail[i]=0,因为无法构成相同前后缀
2. $fail[i-1] \neq 0$
- b[i]=b[fail[i-1]+1] 此时可以扩展前面的相同前后缀,如图:
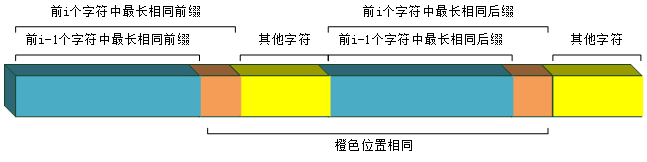
- b[i]!=b[fail[i-1]+1] 此时尝试缩短前缀,也就是再依次判断第i个字符与第fail[fail[i-1]]+1个字符是否相等,直到有两个这样的字符相等或是走到了0.
有了fail数组就可以实现KMP算法了。设模式串中已经匹配了$j$个字符,目标串中对比到了第$i$个字符,则:
- 若a[i]=b[j+1],则下个字符匹配成功,j++;
- 若a[i]!=b[j+1],则沿着fail数组向前查找,缩短匹配部分至前缀;
- 若j=$l_2$,则找到了一个匹配位置。
代码如下:
#include <cstdio>
#include <cstdlib>
#include <cstring>
const int MAXN = 1000000;
int KMP(char* a,char* b){
int na=strlen(a+1),nb=strlen(b+1); //注意+1
static int fail[MAXN+5];
int cnt=0;
//Init
fail[1]=0;//! static在每次进入函数时保留上次修改的值
for(int i=2; i<=nb; i++){
int j=fail[i-1];//尝试扩展已经匹配部分
//无法匹配则缩短匹配部分到前缀
while(j!=0 && b[j+1]!=b[i]) j = fail[j];
//用已经匹配部分更新fail数组
if(b[j+1] == b[i]) fail[i] = j+1;// !!
//无法匹配前后缀
else fail[i] = 0;
}
//Match
for(int i=1,j=0; i<=na; i++){
//缩短匹配部分到前缀
while(j!=0 && b[j+1]!=a[i]) j = fail[j];
if(b[j+1] == a[i]) j++; //成功匹配一个字符
if(j==nb){
cnt++;
j=fail[j];
//j=0; //如果两个匹配部分不可重叠
}
}
return cnt;
}
int main(){
int T;
char a[MAXN+5],b[MAXN+5];
scanf("%d",&T);
while(T--){
//从1开始存储,因为fail数组中0代表没有相同前后缀
scanf("%s",b+1);
scanf("%s",a+1);
printf("%d\n",KMP(a,b));
}
return 0;
}
UPD: 上面L16错了半年才发现,应该是j+1 ……